-
 Continue reading →: Threat Hunting and Defending #2: frameworks (p1)
Continue reading →: Threat Hunting and Defending #2: frameworks (p1)Intro Nel primo post di questa serie ho riportato soprattutto la teoria della disciplina e l’estrema sintesi è che il Threat Hunting è un processo strutturato utile ad identificare e mitigare minacce informatiche che i sistemi di detection non hanno potuto rilevare a causa di limiti del sistema (e di…
-
 Continue reading →: Docker ad uso personale
Continue reading →: Docker ad uso personaleIn molti ambiti dell’IT capita di costruirsi piccoli tools per automatizzare alcuni task o rendere più comodo alcune operazioni e solitamente questi tools vengono utilizzati localmente sulle proprie workstation/laptop. Più di recente mi è capitato di dover automatizzare operazioni con strumenti che avrei poi dovuto spostare su altri host e…
-
Continue reading →: Cloaking, SEO e minacce via web.
Altra tecnica datata ma molto efficace in determinati contesti: il cloaking. Va detto, per prima cosa, che il cloaking è una tecnica considerata poco etica nel mondo della SEO. Consiste nel verificare la provenienza dell’utente per decidere che contenuti presentare, spesso era usata per dare in pasto ai BOT dei…
-
 Continue reading →: Come funziona un Command and Control (C2)
Continue reading →: Come funziona un Command and Control (C2)Chi segue il blog o il canale YouTube da un po’ è a conoscenza dei miei obiettivi divulgativi: storicamente ho sempre scritto e parlato dei temi che riguardavano il mio quotidiano ma da qualche mese sto cercando di proporre temi che siano utili a chi ha iniziato da poco il…
-
Continue reading →: TTP-based Threat Hunting
Il titolo di questo post riprende, volutamente, il documento di MITRE a cui si ispira: 36 pagine di saggezza che, se lavori nel mondo della cyber security, devi leggere, assimilare e comprendere molto bene. L’obiettivo è solo introdurre il tema ed evidenziare i motivi che lo rendono importante sia per…
-
Continue reading →: Threat Hunting and Defending #1: intro
Premessa Ricomincio a studiare per una nuova certificazione Cyber Security e quest’anno ho scelto “Conducting Threat Hunting and Defending using Cisco Technologies for Cybersecurity“. Giustamente molti, già lo scorso anno, mi avevano scritto incuriositi da quella che poteva sembrare una deriva Defense (non che ci sia nulla di male), considerando…
-
 Continue reading →: Giochiamo insieme #1
Continue reading →: Giochiamo insieme #1Premessa Ho pensato di proporre, su LinkedIn, delle piccole challenge dedicate alla sicurezza offensiva: semplici scenari di attacco che prendo dal mondo vero (cose che a tutti i PenTester sono successe). Ho decisi di proporre questo “gioco” su LinkedIn perché i contenuti della piattaforma stanno letteralmente andando a ramengo, per…
-
 Continue reading →: Postcast live (test)
Continue reading →: Postcast live (test)Qualche giorno fa assieme ad Andrea abbiamo provato ad eseguire lo stream di una puntata podcast. Si trattava di una puntata di test che avevamo pensato di fare dall’ufficio di Bolzano di NTS (entrambi lavoriamo nella stessa azienda) ma che non siamo riusciti a realizzare nella versione streaming. Mi correggo:…
-
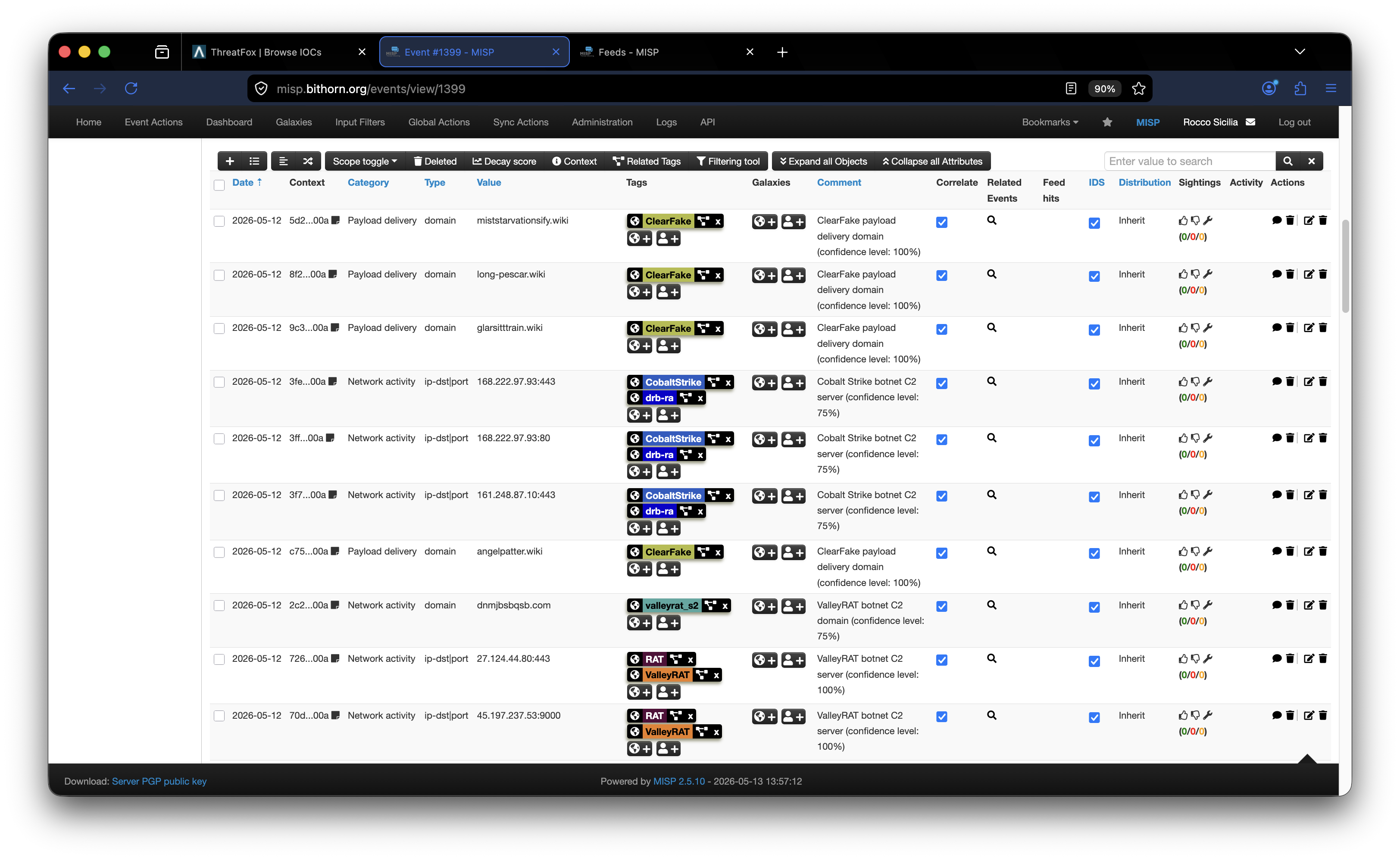 Continue reading →: MISP how-to: integrazione di feeds
Continue reading →: MISP how-to: integrazione di feedsPremessa Questo post riprende una serie di contenuti che avevo in roadmap sul tema MISP e vorrei farlo discutendo alcuni use case su cui sto lavorando. Come alcuni sanno tempo fa ho iniziato a lavorare ad un progetto community per promuovere attività di Cyber Threat Intelligence e con l’occasione abbiamo…
Ciao e benvenuto/a sul mio blog,

il mio nome è Rocco Sicilia e su queste pagine condivido idee, riflessioni ed esperienze su hacking e sicurezza informatica.
Let’s connect
Rimani aggiornato!
Iscriviti per ricevere gli update dei nuovi post e video.