Rocco Sicilia
Search
Home
About me
Divulgazione
Sostieni il progetto
English version
Mese:
gennaio 2023
Cyber Saturday 20230121
Threat-Led Penetration Testing
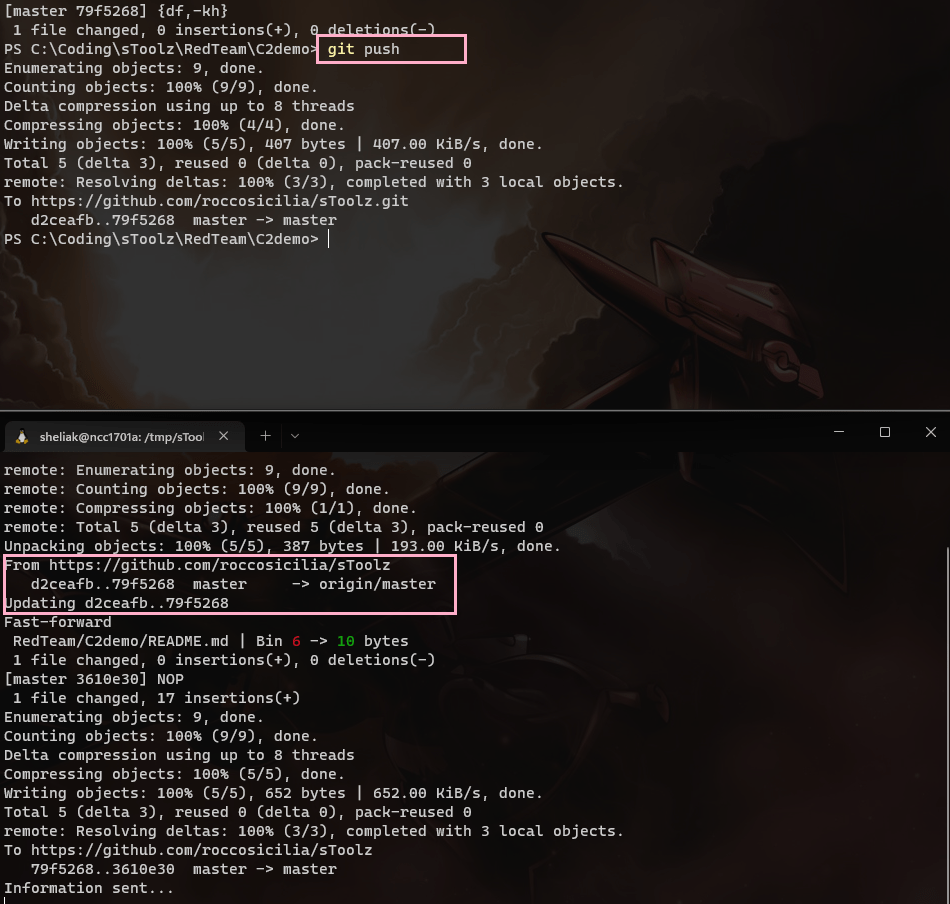
GIT-SHELL: p-o-c v0.1
Una riflessione sul concetto di “detection”
La qualità del software e l’impatto sulla vita
I report (in cyber sec.)
OSCP-D1
Abbonati
Abbonato
Rocco Sicilia
Unisciti ad altri 48 abbonati
Registrami
Hai già un account WordPress.com?
Accedi ora.
Rocco Sicilia
Abbonati
Abbonato
Registrati
Accedi
Segnala questo contenuto
Visualizza sito nel Reader
Gestisci gli abbonamenti
Riduci la barra