-
 Continue reading →: Parent Process ID Spoofing
Continue reading →: Parent Process ID SpoofingContinuiamo la serie di laboratori sulle tecniche di evasione prima di prenderci una pausa per valutare qualche strategia di difesa. Il nome della tecnica (rif. al titolo del post) è decisamente chiaro: si tratta di modificare una delle informazioni che caratterizzano i processi, ovvero l’ID del processo padre. Perché dovremmo…
-
 Continue reading →: Notification Callback Routines e CommandLine tampering
Continue reading →: Notification Callback Routines e CommandLine tamperingLa questione detection si comincia a fare interessante a partire da questa funzionalità che – IMHO – fa sembrare il function hooking una modo “grezzo” di approcciare il problema. Ovviamente non è mia intenzione criticare metodi di detection che ci hanno aiutato per anni e continuano ad aiutarci, ma penso…
-
 Continue reading →: Web Filtering
Continue reading →: Web FilteringLa puntata è uscita da qualche giorno e con i nuovi potentissimi tools sul sito del podcast trovate anche la sintesi auto-generata tramite LLM. L’argomento per molti potrebbe sembrare banale ma quello che ho potuto osservare durante i security test è che le funzionalità di web filtering, che solitamente avete…
-
 Continue reading →: Detection e function hooking
Continue reading →: Detection e function hookingL’introduzione fatta ai concetti di detection mi serviva per iniziare a discutere del funzionamento degli EDR partendo da una base comune di comprensione dell’architettura. Come ho anticipato questi post hanno lo scopo di discutere anche le possibile tecniche di bypass delle logiche di detection con degli esempi pratici e mi…
-
 Continue reading →: Il concetto di detection e il punto di vista offensivo
Continue reading →: Il concetto di detection e il punto di vista offensivoQuesta miniserie è collegata alla serie sui lab-test che prevedono test offensivi e lo studio della detection. Diciamo che in realtà è la stessa serie declinata in due modi diversi: nel lab gli aspetti pratici e gli “esperimenti”, qui i concetti in parte estratti da alcuni testi e risorse prese…
-
Continue reading →: Cisco Live 2026
Premetto che non ero presente all’evento di Amsterdam da cui manco ormai da qualche annetto ma c’era Andrea 🙂 e visto che eravamo anche in ritardo per la registrazione della puntata podcast ci siamo sentiti e mi sono fatto un po’ raccontare. Personalmente l’evento mi è sempre piaciuto ed a…
-
 Continue reading →: Cyber Frontiers 2026
Continue reading →: Cyber Frontiers 2026Prima qualche dato tecnico: “CyberFrontiers nasce dall’idea di professionisti appassionati di sicurezza informatica e tecnologia, con l’obiettivo di creare unponte tra il mondo tecnico e quello aziendale. Unisce esperti, community e imprese in un unico ecosistema, favorendo networking, condivisione e crescita.” Così recita l’about della pagina LinkedIn che ho voluto…
-
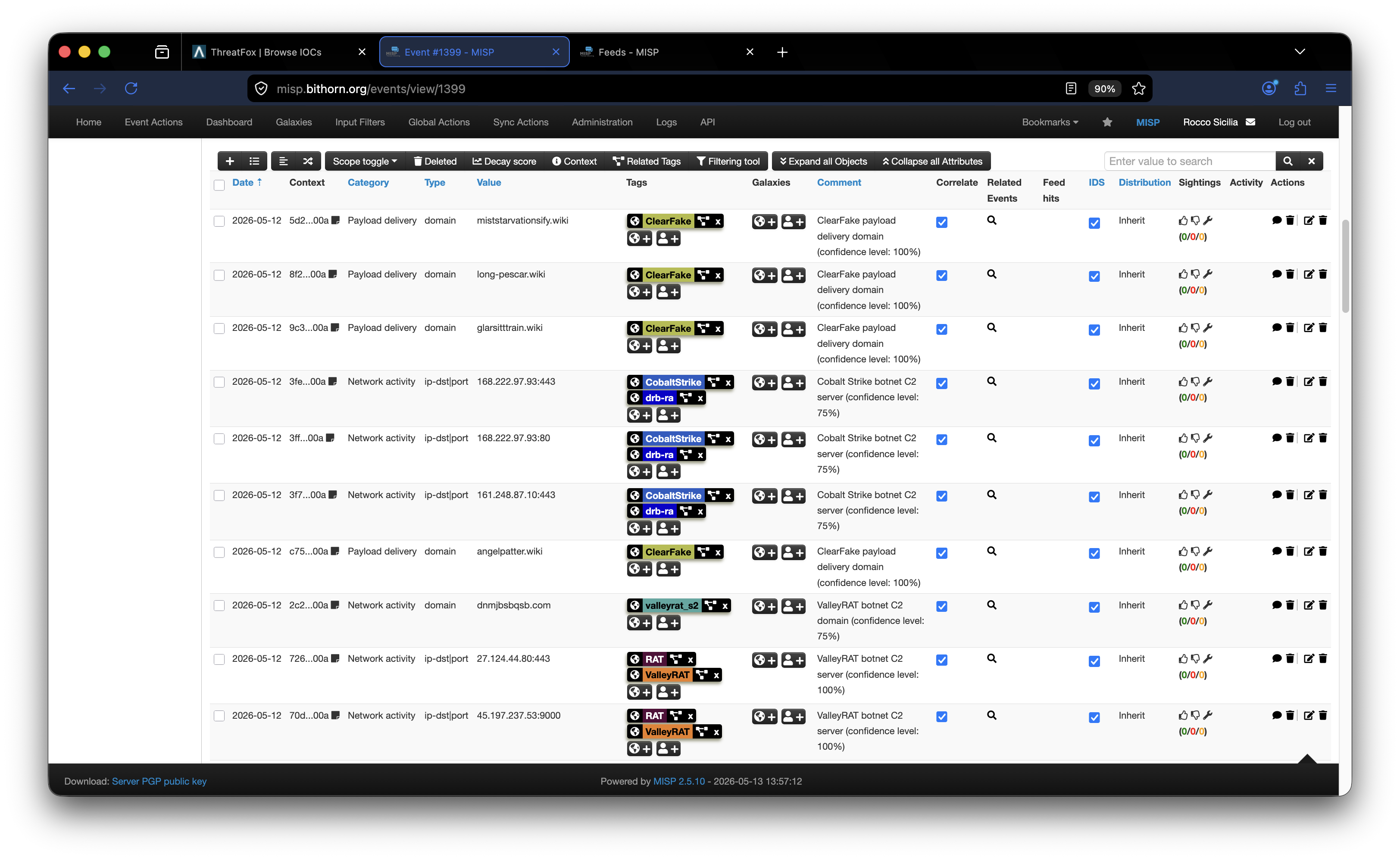
 Continue reading →: Analisi di un C2 per OSX
Continue reading →: Analisi di un C2 per OSXStavo cercando un documento in PDF per mio figlio, una delle tante ricerche, ed uno dei risultati di ricerca era questo sito (ancora online al momento della pubblicazione del post): Chi è del mestiere, nel vedere un sito che ti dice di eseguire un comando sul tuo terminale, sente già…
-
 Continue reading →: HomeLab – Intro
Continue reading →: HomeLab – IntroCome detto in questo post su LinkedIn dedico qualche articolo (e video) al mio HomeLab con lo scopo di pubblicare i dettagli tecnici della struttura che ho scelto e renderlo replicabile per chiunque sia interessato a smanettare con dei test di laboratorio in ambito info sec. Nel mio caso l’esigenza…
Ciao,
sono Rocco

… e questo è mio sito personale dove condivido idee, riflessioni ed esperienze su hacking e sicurezza informatica.
Let’s connect
Rimani aggiornato!
Iscriviti per ricevere gli update dei nuovi post e video.