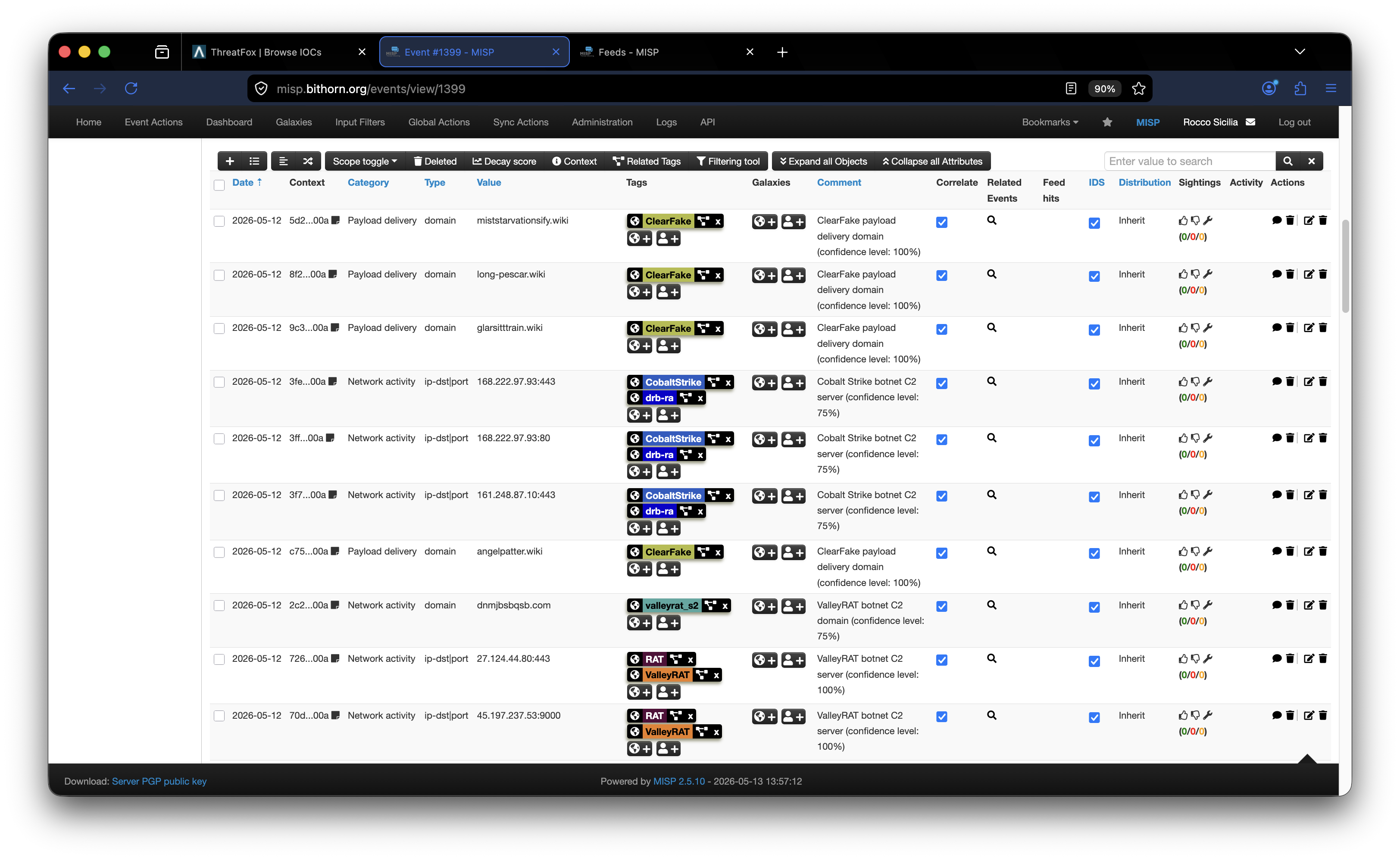
-
 Continue reading →: IDS, IPS ed analisi del traffico
Continue reading →: IDS, IPS ed analisi del trafficoQualche giorno fa ho parlato di traffic sniffing, argomento che mi avrebbe portato a parlare di Intrusion Detection/Prevention System e ad una ulteriore evoluzione del lab e dei test che potrò/potremo fare. Ho parlato di questi strumenti nella serie dedicata ai temi Defense su Patreon che eventualmente potete utilizzare per…
-
 Continue reading →: Info Sec Unplugged – CISO e vCISO
Continue reading →: Info Sec Unplugged – CISO e vCISOLe ultime due puntate del podcast, che in realtà sono la prima e la seconda parte di una unica registrazione, sono tornate su un tema che sia io che Andrea, nonostante il nostro percorso professionale storicamente molto orientato al campo tecnico, abbiamo affrontato in prima persona: l’esigenza di molte organizzazioni…
-
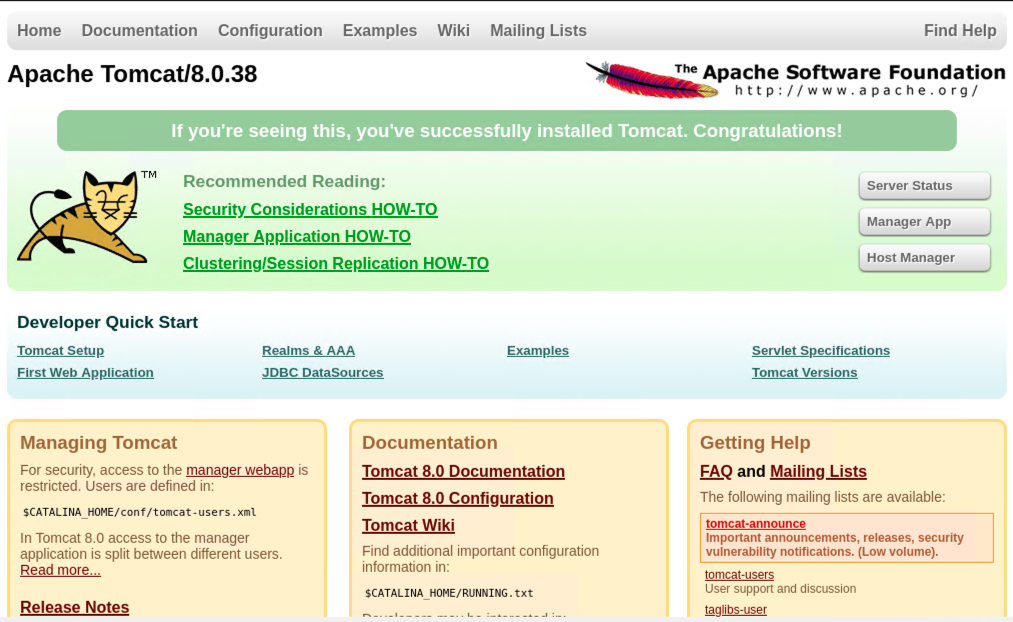 Continue reading →: Exploit test (con ghostcat)
Continue reading →: Exploit test (con ghostcat)Potrebbe essere un po’ impopolare come opinione, sono comunque convinto che per capirci veramente qualcosa nel mondo del Penetration Testing bisogna veramente immergerti nella melma e dedicare tempo a cose che hanno a che fare con l’informatica molto prima di iniziare a toccare i temi info. security. Non mi avventuro…
-
 Continue reading →: Punto di “sniffing”
Continue reading →: Punto di “sniffing”In questi giorni ho rimesso mano al mio home lab aggiungendo qualche pezzo ed in particolare mi sono dotato di una componente hardware che solitamente, per esigenze di spazio e comodità, utilizzavo nelle sue versioni software e decisamente più limitate: lo switch. Purtroppo non ho la possibilità di installare un…
-
Continue reading →: Dove avete messo il vostro codice?
Tantissime aziende che di “mestiere” non scrivono codice si trovano a dover implementare piccole integrazioni o piccoli tools che nel tempo, in alcuni casi, diventano anche sistemi core per l’azienda. Personalmente mi è capitato spesso di incontrare team IT che si erano scritti il proprio tool per la gestione di…
-
Continue reading →: API ed info-sec
Sono impegnato, in questo periodo, nello studio per una certificazione Cisco in ambito Cyber Defense (i motivi li ho spiegati qui) e ho trovato molto interessante il fatto che un’intero capitolo sia stato dedicato al tema API ed integrazioni. È, ancora una volta, una questione di approccio: chi da per…
-
![Info Sec Unplugged [1e] – Gestione delle configurazioni](https://roccosicilia.com/wp-content/uploads/2024/12/podcast.png) Continue reading →: Info Sec Unplugged [1e] – Gestione delle configurazioni
Continue reading →: Info Sec Unplugged [1e] – Gestione delle configurazioniCome ho raccontato nella intro che ho fatto su YouTube la scelta di parlare dei temi (i controlli) legati alla ISO 27001 viene da passate e presenti esperienze vissute sia da me che da Andrea in merito a come, spesso ma non sempre, vengono approcciate le certificazioni da parte delle…
-
Continue reading →: Speedrunning the Cyber Kill Chain
Questo post esce poco dopo rispetto alla mia presentazione al Cyber Security Day organizzato da ATED il 29 ottobre a Lugano. Il workshop che ho presentato aveva l’obiettivo di illustrare in modo pratico ed in 30 minuti – anzi 25 🙂 l’organizzazione ed il mitico Luca Mauriello sono stati molto…
-
Continue reading →: Info Sec Unplugged [1d] – DR e Cyber recovery (puntata speciale)
Ultima puntata di questa mini serie in cui abbiamo approfittato della saggezza di Mattia Parise che si è unito a me ed Andrea per discutere in dettaglio di Cyber recovery. Non voglio fare spoiler visto che la puntata è in uscita – la troverete disponibile dal 03.11.2025 – quindi vi…
Ciao,
sono Rocco

… e questo è mio sito personale dove condivido idee, riflessioni ed esperienze su hacking e sicurezza informatica.
Let’s connect
Rimani aggiornato!
Iscriviti per ricevere gli update dei nuovi post e video.