In molti contesti operativi e formativi si fa riferimento alla ricerca di informazioni utilizzando modalità “passive”, ovvero senza un contatto diretto con il target, utilizzando il termine Open-source Intelligence (OSInt). Parere assolutamente personale: OSInt è sicuramente una tecnica utile all’Info. Gathering ma non credo sia l’unica modalità per procedere.
Al netto di questa mia nota vi sono due principali approcci. Il primo prevede zero interazione con il target, di nessun tipo e per nessuna ragione: questo modo di procedere consentirebbe all’analista di mantenere il massimo livello di discrezione sulle attività ricognitive. Il secondo metodo prevede un’interazione limitata a ciò che un normale utente potrebbe fare, come visitare io sito web del target o iscriversi a dei servizi gestiti dall’organizzazione oggetto dell’attività. In un contesto di simulazione di attacco probabilmente è più sensato agire con la seconda modalità: un threat actor non ha ragione di non raccogliere info interagendo – con le dovute cautele – con uno o più sistemi del target. Avendo diverse opzioni è opportuno valutare il modello in fase di ingaggio.
Esistino moltissime informazione che potremo indagare sul target ed il processo non è lineare: ogni nuovo elemento scoperto potrebbe avviare una nuova processo di ricerca nel constesto che siamo indagando o su nuovi fronti. L’obiettivo deve sempre essere quello di mattale la “superfice” del target nel miglior modo possibile.
Domain Name
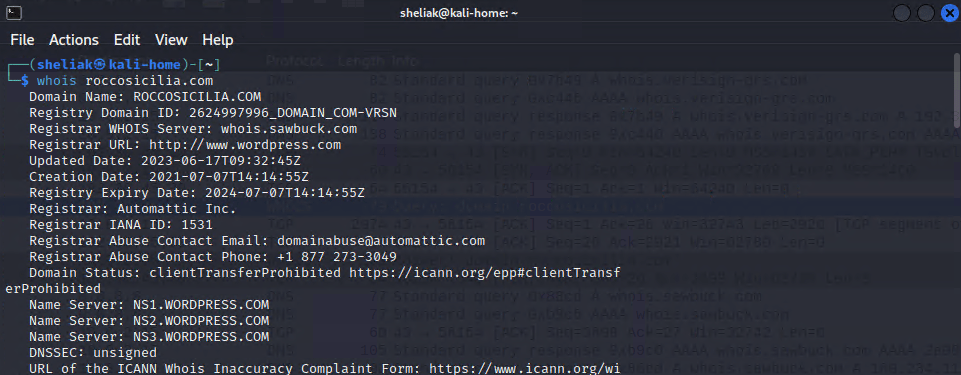
Probabilmente la cosa più logica è partire dai nomi dominio legati al target. Un tool molto semplice da utilizzare a questo scopo è whois, un’applicazione che di base esegue una richiesta a delle fonti esterne e pubbliche in relazione alle informazioni dei nomi dominio. Le info. sui nomi dominio sono gestiste e rese fruibili dagli whois server, non è necessario conoscere un server per eseguire una query in quanto ci pensa il servizio DNS a dirci a chi possiamo rivolgerci.
Semplificando al massimo quando facciamo una richiesta whois dal nostro client con il comando “whois roccosicilia.com” avvengo le seguenti azioni:
- viene chiesto al DNS il server whois di riferimento
- nella risposta viene fornito il server che viene usato per la richiesta whois
- viene eseguita la richiesta come da specifiche del protocollo whois al server corretto (rfc 3912)
- il client riceve la risposta dal server whois e la stampa
A livello client è tutto molto semplice:
Potrebbe essere interessante vedere cosa avvade a livello TCP utilizzando un tool come Wireshark (avremo modo di approfondirlo) per analizzare le richieste TCP del nostro client e le risposte del server. Prendiamo in considerazione sono una parte del traffico e partirei dalla risposta del DNS in relazione al server whois da usare nella query:

E’ ben visibile l’IP del server di riferimento associato al mio domain name: 192.30.45.30. Sulla destra il contenuto raw del pacchetto dove vediamo il relativo esadecimale dell’IP che abbiamo avuto in risposta (in forma decimale): c0 1e 2d 1e. La query whois viene quindi eseguita verso il server indicato nella risposta del DNS e sarà quindi questo server ad inviarci il testo in risposta.
Se conosciamo il server whois nessuno ci vieta di eseguire una richiesta diretta, senza passare dal DNS, specificando il server con il parametro -h:
$ whois roccosicilia.com -h 192.30.45.30Ci sono diverse informazioni che posso essere interessanti nella risposta del server whois:
- Registrant Name: chi “possiede” il dominio
- Admin Name: chi gestisce la zona DNS del dominio
- Tech Name: il riferimento tecnico per la noza dns
- Name Server: i sistemi responsabili della gestione della zona DNS
Non è raro trovare i primi due dati non disponibili per un tema di privacy, in passato era fin troppo semplice accedere ai riferimenti delle persone fisiche che gestivano i nomi dominio. Si possono comunque raccogliere dati interessanti in relazione al provider scelto dal target per la gestione dei DNS, nel mio caso NS[1-2-3].WORDPRESS.COM avendo un dominio registrato con il servizio wordpress.com.
In molti casi, soprattutto nel mondo Corporate ed Enterprise, il provider potrebbe essere la stessa azienda coinvolta nello sviluppo del sito aziendale o di applicazioni web che il target utilizza. In un contesto di ricognizione più ampio è quindi sensato appuntare anche queste informazioni in quanto è probabile esista una relazione tra il nostro target e figure del provider individuato.
Per quanto possano sembrare pochi dati la struttura potrebbe essere da subito molto complicata: un Domain Name da riferimento ad diverse informazioni a loro volta da strutturate come liste di aziende, persone, servizi esterni, IP range, FQDN, ecc. Mettere tutto in un unico documento limita la visibilità allo scope dell’attività in corso mentre strutturare un Database potrebbe aiutare a gestire le relazioni tra i dati nel tempo.
Con mio stupore la documentazione inerente alcune certificazioni non va oltre whois in relazione all’enorme mondo di servizi CORE per internet come è il servizio DNS classificando la DNS enumeration con azione attiva e non passiva, personalmente non concordo al 100%, mi permetto quindi qualche anticipazione in questa sede.
Analisi della zona DNS
Vorrei dare solo qualche spunto su argomenti che ho ampiamente trattato in vari articolo, live, workshop, ecc. La zona DNS mette a disposizione una montagna di informazioni sul perimetro del target. Con una semplicissima utility come dig o nslookup possiamo chiedere informazioni specifiche ai Name Server sul domonio che stiamo analizzando. Facciamo una prova con un dominio chiedendo i record di tipo TXT:
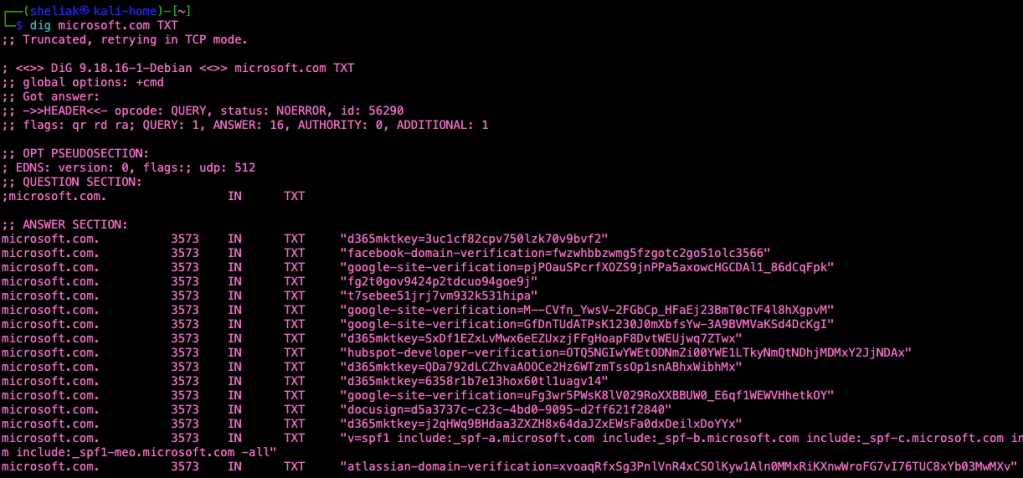
Nei record vengono posizionate delle informazioni necessarie al target per utilizzare correttamente alcuni servizi come la posta elettronica o servizi cloud legati al domain name. E’ quindi possibile raccogliere ulteriori informazioni sul perimetro, in questo caso appare evidente che probabilmente il target utilizza un servizio cloud di Atlassian che probabilmente ha una URL pubblica.
Search Engine
Una quantità enorme di informazioni possono essere raccolte grazie ai motiri di ricerche che hanno la particolarità di esplorare porzioni enormi del web di superficie e sono in grado di rendere disponibili informazioni specifiche grazie alle query di ricerca. In assoluto il motore di ricerca più noto ed usato anche a questo scopo è Google e la pratica del Google Hacking è quella più frequentemente citata nella documentazione delle certificazioni in ambito Cyber Sec., ma trovo poco saggio non valutare anche gli altri strumenti di ricerca. Una risorsa utile è sicuramente il famigerato libro “Google Hacking for Penetration Testers” di cui è ancora possibile acquistare una copia e di cui non mancano le copia PDF distribuite in modo in po’ troppo smaliziato… paradossalmente basta una ricerca su Google per trovarle.
Il funzionamento delle query è molto semplice e si basa sul concetto della ricerca per chiave:valore. Esempio, se voglio un elenco delle entry relative al mio sito web posso fare una ricerca per “site” come chiave e “roccosicilia.com” come valore:
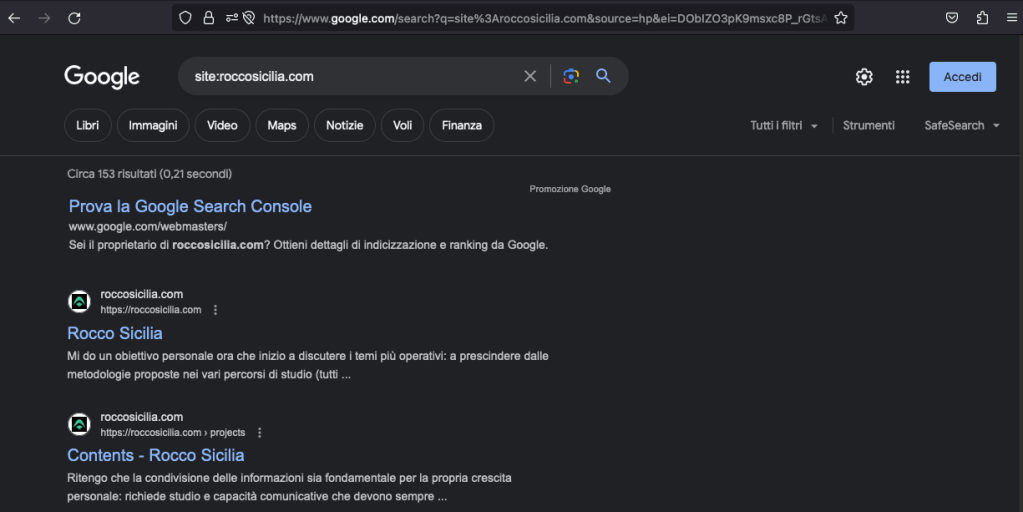
E’ possibile affinare ulteriormente la ricerca aggiungento parametri, ad esempio richiedendo contenuti con una estensione specifica:

Questa tecnica potrebbe essere utilizzata per trovare risorse utili dal punto di vista dei security test come file di configurazione, documenti interni erroneamente condivisi, logs, informazioni sul target e/o sui collaboratori. Il limite in questo caso è la fantasia e l’esperienza del PenTester.
Analisi delle risorse web
Una volta individuati i sistemi del target è necessario comprendere di che ambienti si tratta: il tipo di hosting, le tecnologie in uso, le configurazioni dei sistemi. Per eseguire questo tipo di analisi in modo passivo è necessario utilizzare sistemi e servizi che raccolgono queste informazioni per i propri scopi. Servizi come NetCraft con il suo https://sitereport.netcraft.com/ o Shodan possono aiutare a raccogliere molte informazioni. In particolare Shodan è spesso citato per il mondo IoT di cui effettivamente è ricco di informazioni, ma una ricerca su un IP di un web server può restituire moltissime informazioni sul sistema target.
Altra grande fonte di informazioni sono le repository di codice come GitHub e GitLab: non è da escludere che il target utulizzi questo tipo di servizi per condividere informazioni o gestire e contribuire a progetti open-source. Potremmo individuare del codice in uso dal target analizzando questa risorsa.
Analisi degli Headers SSL e TLS
Elemento estremamente trascurato, la configurazione dei servizi HTTP può dare al threat actor spazio per utilizzare una nostra risorsa contro di noi. Per eseguire un controllo è sufficiente utilizzare uno dei tanti siti che analizzano la risposta HTTP del sito web target per verificare se mancano configurazioni utili:
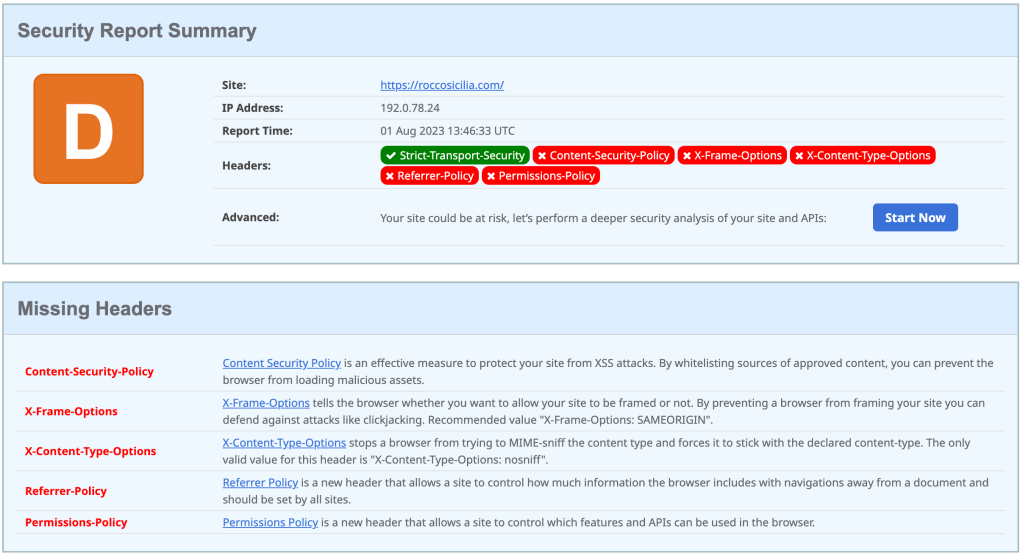
Nel caso del mio web server, gestito direttamente da WordPress, mancano alcuni headers con X-Frame-Options.
Altri elementi
Nei percorsi tipici dell’ambito Penetration Testing raramente incontro il tema e approfitto dell’occasione per prende brevemente in considerazione l’ambito “umano”. Le aziende sono fatte anche di persone ed in una fare ricognitiva ha senso farsi un’idea di chi sono i collaborati del target in relazione a ruoli, competenze, certificazioni. Così come potrebbe essere utile comprendere le relazioni con l’esterno e gli interlocutori come clienti e fornitori.
Un’ottima fonte per questo tipo di informazioni sono i social network, su in relazione alle singole persone che in relazione alla corporate: non è raro che le aziende abbiano pagine dedicate su varie piattaforme social e tipicamente vengono utilizzare per condividere informazioni.
Note conclusive
Il processo di ricerca può andare anche molto in profondità e le note su dati cosi diversi possono diventare parecchio confuse. Come già detto nel precedente post in tema di info. gathering è indispensabile trovare un modo efficacie di documentare le informazioni.
Non lasciate nulla al caso: per ogni dato, se vi è possibile, approfondite eventuali elementi aggiuntivi e verificare eventuali “collegamenti” con altre informazioni rilevate. Tenete a mente che non è un processo lineare, ogni elemento potrette richiedere approfondimenti su dati che avete già analizzato.
Per esperienza personale penso abbia perfettamente senso fare ipotesi: riempite i “buchi” ipotizzando la presenza di elementi verosimili e cercare elementi a supporto delle ipetesi. In questa fase è molto importante avere una buona “big picture” del target.






Lascia un commento