Premetto che in questo post mi avventuro su un tema non propriamente mio (la statistica) applicato al campo della cyber security (che è un po’ più casa mia). Colpa di Mirko Modenese – uno che di statistica ne sa da far cuccioli – che mi tira in ballo in questo suo post.
Nel citato post Mirko fa riferimento al Metodo Monte Carlo, una tecnica di simulazione basata sul campionamento randomizzato. Come dicevo non è esattamente il mio terreno di gioco quindi non ho gli strumenti per spiegare decentemente di cosa si tratta ma ricordavo di aver già letto qualcosa in merito in relazione alla possibilità di calcolare il rischio di una specifica misura (come ad esempio un security test o un vulnerability assessment) utilizzando diversi insiemi di valori randomizzati. Così utilizzata questa tecnica consentirebbe di ottenere diversi possibili risultati in relazione ai possibili valori di rischio ottenibili.
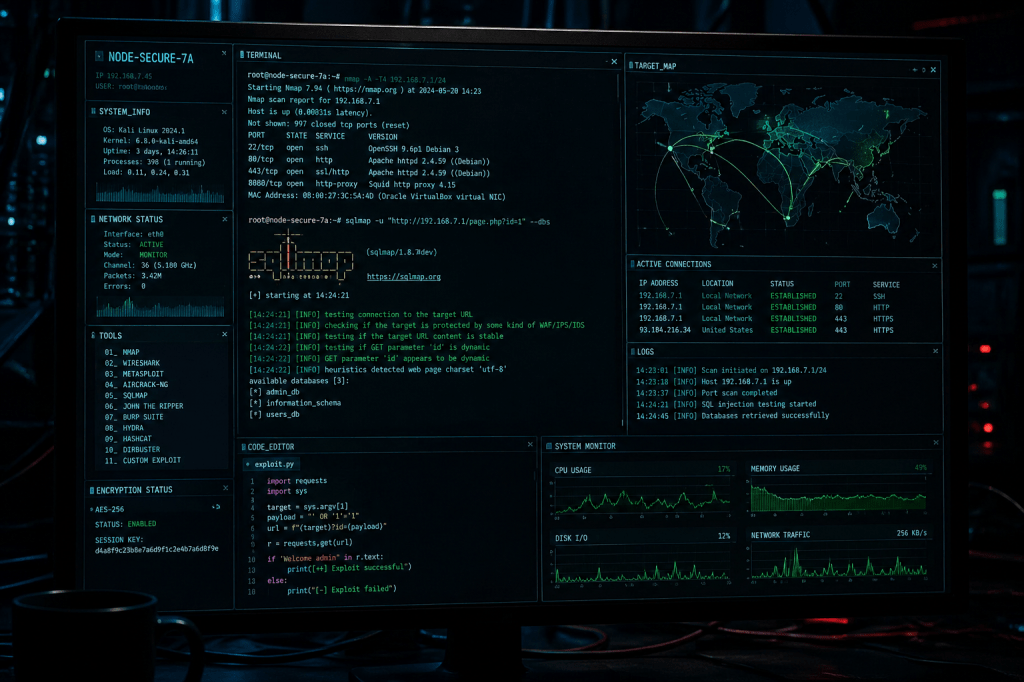
E’ un modello che trovo molto interessante soprattutto in considerazione del metodo tradizionalmente utilizzato in molti contesti, tra cui anche le attività di Red Teaming come i citati vulnerability assessment, in cui vengono utilizzati parametri estremamente statici e spesso decontestualizzati per fornire delle stime di rischio totalmente inesatte. Un esempio tipico è l’utilizzo del CVSS score come parametro di rischio quando è un valore che si riferisce alla vulnerabilità e prescinde il contesto. Per calcolare il rischio correlato servono diversi altri valori che l’analista deve in parte definire in funzione del contesto ed in parte stimare o assegnare in base alla propria esperienza e comprensione della specifica vulnerabilità, tenendo in considerazione le possibilità che la vulnerabilità sia sfruttabile o meno in un prossimo futuro.
Quando si eseguono queste valutazioni (e se si eseguono… ho notato che è un tema affrontato da pochi Red Team) potrebbe essere necessario fare delle ipotesi e potrebbe anche essere molto utile tentare di quantificare economicamente il rischio. In questi casi l’applicazione del Metodo Monte Carlo diventa estremamente utile in quanto consente di produrre delle simulazioni realistiche su cui poi basare nuove analisi e, se possibile, decisioni.
Ho incontrato per la prima volta questo approccio in un libro di Hubbard: “How to Measure Anything in Cybersecurity Risk”. All’interno del mio Red Team non ci siamo ancora trovati a fare modellazioni a questo livello ma gli spunti sono stati molti per arrivare a ottenere una misurazione del rischio che sia contestualizzata rispetto al target. Nel caso specifico cerchiamo di disporre di dati oggettivi sul sistema osservato da portarli poi in analisi assieme alle misurazione degli strumenti di rilevamento; dati come il business impact o la tipologia di dato gestito tramite il sistema oggetto dell’assessment diventano quindi elementi essenziali per una corretta stima del rischio.
E’ anche vero che in molti contesti parte di questi dati, tipicamente a carico del cliente, non sono disponibili per diversi motivi: alcune di queste informazioni dovrebbero far parte di sistemi di gestione come l’asset manager o potrebbero essere derivanti da un risk assessment. Nasce quindi l’esigenza di disporre di un metodo che consenta la definizione di modelli realistici anche con dati parziali.
Per approfondire il tema servirebbe proprio Mirko, quindi mi riprometto di coinvolgerlo in una live per vedere come possiamo applicare il Metodo Monte Carlo ad un caso specifico. Tema affascinante e per nulla banale.




Lascia un commento